ProcessMiner™ Manufacturing Industry Case Studies
ProcessMiner™ Director of Science, Chitta Ranjan, shares his extensive research on data in the manufacturing industry.

Paper Mill Saves $600K Annually With Chemistry Quality Control Automation
ProcessMiner Delivers 25% Reduction in Wet Strength Chemistry Usage

How Board Mill Optimizes Kymene Consumption
ProcessMiner Delivers 25% Reduction in Wet Strength Chemistry Usage

How Tissue & Towel Manufacturer Reduced Chemistry Use by 25%
ProcessMiner Delivers 25% Reduction in Wet Strength Chemistry Usage

How a Paper Board Mill Lowered Chemistry Dosage by 18%
ProcessMiner Delivers 25% Reduction in Wet Strength Chemistry Usage

How Board Producer Reduced Chemistry Consumption by 14%
ProcessMiner Delivers 25% Reduction in Wet Strength Chemistry Usage

Optimizing Wastewater Treatment With ProcessMiner
AI-powered Platform Delivers 25 Percent Reduction in Scrap Rates

How a Plastic Injection Molding Manufacturer Reduced Scrap Rates by 25%
ProcessMiner Delivers 25% Reduction in Scrap Rates
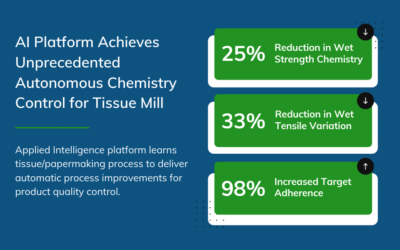
Artificial Intelligence Platform Achieves Unprecedented Autonomous Chemistry Control for Tissue Mill
The goal of this project was to autonomously control part of a tissue mill’s continuous manufacturing process using artificial intelligence and predictive analytics to reduce raw material consumption while maintaining the product quality with specification limit.
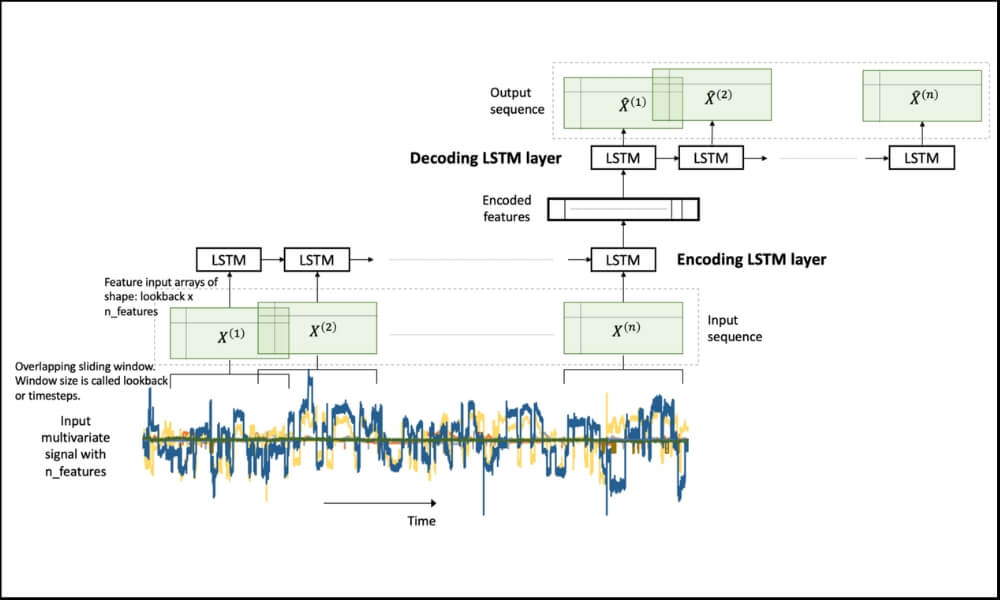
LSTM Autoencoder for Extreme Rare Event Classification in Keras
Here we will learn the details of data preparation for LSTM models, and build an LSTM Autoencoder for rare-event classification. This post is a continuation of my previous post-Extreme Rare Event Classification using Autoencoders. In the previous post, we talked about the challenges in an extremely rare event data with less than 1% positively labeled data.
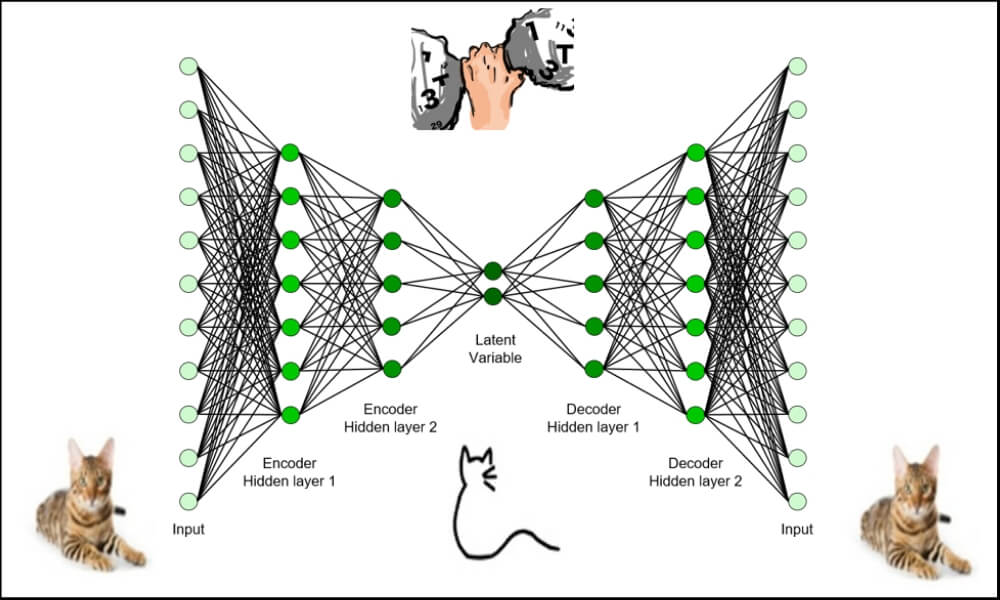
Extreme Rare Event Classification using Autoencoders in Keras
In a rare-event problem, we have an unbalanced dataset. Meaning, we have fewer positively labeled samples than negative. In a typical rare-event problem, the positively labeled data are around 5–10% of the total. In an extremely rare event problem, we have less than 1% positively labeled data.

Estimating Non-Linear Correlation in R
Correlation estimations are commonly used in various data mining applications. In my experience, nonlinear correlations are quite common in various processes. Due to this, nonlinear models, such as SVM, are employed for regression, classification, etc.

Sequence Embedding for Clustering and Classification
Here we will learn an approach to get vector embeddings for string sequences. These embeddings can be used for Clustering and Classification. Sequence modeling has been a challenge. This is because of the inherent un-structuredness of sequence data. Just like texts in Natural Language Processing (NLP), sequences are arbitrary strings.

Dataset: Rare Event Classification in Multivariate Time Series (Pt. 2)
Researchers are often looking for interesting real-world problems. One major roadblock they face is real-world data. Here we are trying to serve the research community by providing a real-world problem and a dataset. This dataset is created from the pulp-and-paper manufacturing industry. Paper sheets are not the strongest material.

Dataset: Rare Event Classification in Multivariate Time Series (Pt. 1)
A real-world dataset is provided from the pulp-and-paper manufacturing industry. The dataset comes from a multivariate time series process. The data contains a rare event of paper break that commonly occurs in the industry. The data contains sensor readings at regular time-intervals (x’s) and the event label (y).
Contact Our Data Science Team
Fill out the form below and we’ll get back to you, or contact us by phone to speak to a miner today.
Have a project in mind?
For more information, download our brochure. We’ll reach out to you!
U.S. Headquarters
75 Fifth Street NW
Suite 2505
Atlanta, GA 30308
+1 (678) 463-5799
info@processminer.com
International
INDIA
FINLAND
Oy ProcessMiner Ab
Otakaari 5
02150 Espoo
+358 400 450 748
jvanska@processminer.com